As noted in the page on data compression, text can be represented more efficiently using Huffman coding. Since text is composed of words having lengths in a relatively narrow range, separated from each other by single spaces, a multi-state Huffman code, with one set of symbols for word lengths, and another set of symbols for letters, can be used, and it has the added attraction of obscuring this aspect of the structure of a text document.
Even when it is not intended to perform explicit compression, codes representing characters for transmission can be designed for efficiency.
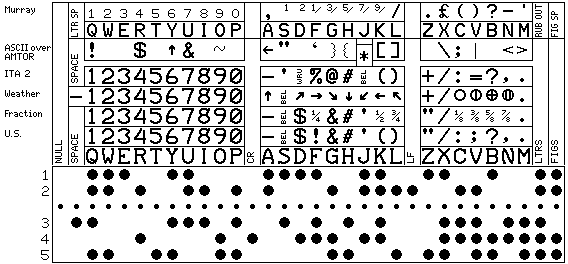
ITA 2, 5-level code, or the Murray code, generally known as Baudot, as it is based on his principle, even if it does not resemble his original code,
uses only five bits to represent a character, but sometimes extra characters are needed to shift between cases.
ASCII requires seven bits per character, and is simpler to use, since no shifts are required:
0 0 0 0 1 1 1 1
0 0 1 1 0 0 1 1
0 1 0 1 0 1 0 1
0000 NUL DLE 0 @ P ` p
0001 SOH DC1 ! 1 A Q a q
0010 STX DC2 " 2 B R b r
0011 ETX DC3 # 3 C S c s
0100 EOT DC4 $ 4 D T d t
0101 ENQ NAK % 5 E U e u
0110 ACK SYN & 6 F V f v
0111 BEL ETB ' 7 G W g w
1000 BS CAN ( 8 H X h x
1001 HT EM ) 9 I Y i y
1010 LF SUB * : J Z j z
1011 VT ESC + ; K [ k {
1100 FF FS , < L \ l |
1101 CR GS - = M ] m }
1110 SO RS . > N ^ n ~
1111 SI US / ? O _ o DEL Delete
But with seven bits per character, the temptation is strong to use a whole 8-bit byte for a character.
Originally, there were many versions of 8-bit ASCII in use, providing extra characters on a number of computer systems. One common 8-bit ASCII character set found on printers was the one which supported the Japanese katakana syllabary; the IBM PC, the Macintosh, and the Atari ST all had their own 8-bit character sets. Today, there is a standard; the Amiga was one of the first computers to use it, but it is also used in most fonts in Microsoft Windows. In this standard, the extra characters consist of 32 additional control characters, followed by 95 printable characters, most of which are accented letters for the major European languages. Characters commonly found on typewriters, including a superscript 2 and 3, but not a complete set of superscripts, for use in typing measurements, are found. Where the OE ligature was originally placed, the arithmetic symbols for multiplication and division were put in the middle of the accented letters, rather than with the new graphic symbols (this part of the standard was still undecided when the Amiga was designed, so those two characters were omitted from its character set; some printers have the original version as a "Unix character set").
Various languages have their own variants of ASCII. Many of them are described and illustrated here, on Roman Czyborra's web page.
While printers often have their own escape code sequences to switch between some of these character sets, today there are ambitious proposals to create a single code to encompass nearly all the world's languages.
There is the 16-bit Unicode character set, and the larger 31-bit ISO 10646 character set which includes it.
For transmitting such characters, an elegant (if somewhat inefficient) scheme which represents all 7-bit ASCII characters in a single byte known as UTF-8 is the current standard.
In UTF-8, characters, considered to have 31-bit values, are encoded as follows:
Character: Representation: 0000000 00000000 00000000 0abcdefg : 0abcdefg 0000000 00000000 00000ABC Defghijk : 110ABCDe 10fghijk 0000000 00000000 ABCDEfgh ijklmnop : 1110ABCD 10Efghij 10klmnop 0000000 000ABCDE fghijklm nopqrstu : 11110ABC 10DEfghi 10jklmno 10pqrstu 00000AB CDEfghij klmnopqr stuvwxyz : 111110AB 10CDEfgh 10ijklmn 10opqrst 10uvwxyz ABCDEfg hijklmno pqrstuvw xyzabcde : 1111110A 10BCDEfg 10hijklm 10nopqrs 10tuvwxy 10zabcde
The capital letters denote bits that must not all be zero. These bits are showed by areas peppered with dots in the diagram below:

This coding has many desirable properties, one of which is that is unambiguous which transmitted bytes begin a character, and which merely continue one. Also, there are no shifted states in the code. This coding also does not affect mechanical sort order of strings.
However, it allows only 2,048 characters to be encoded in two bytes; yet, many existing codes allow over 8,000 Chinese characters to have two-byte codes. Also, this means that every letter in a Greek or Hebrew language document will take up two bytes, and every symbol in a Thai-language document will take three bytes. Being able to shift into a character set appropriate to the language to be used would seem to be an important property for an efficient coding.
If one is prepared to surrender the desirable properties of this coding, there is sufficient room within it that an efficient coding could be created that is compatible with it.
One way this could be done is by adding these codes:
110ABCDe 01fghijk - character ABCDefghijk - shift into mode where 1pqrstuv means character ABCDpqrstuv 1110ABCD 10Efghij 01klmnop - character ABCDEfghijklmnop - shift into mode where 1pqrstuv means character ABCDEfghipqrstuv
and so on. Having the second-last byte, instead of the last byte, of the form 01xxxxxx would indicate shifting into a mode where two bytes of the form 1xxxxxxx xxxxxxxx indicate a character contained in the same 32,768 character expanse as the character whose code was thus modified.
Leaving any of these modes would require the use of a control character, perhaps SO (shift out).
And this would still leave room for an additional set of more efficient codes for characters:
10xxxxxx 0xxxxxxx 10xxxxxx 1xxxxxxx 0xxxxxxx 10xxxxxx 1xxxxxxx 1xxxxxxx 0xxxxxxx
and so on.
These codes would only be available, of course, where one of the shifted modes above was not in use. The shifted modes affect all character codes where the first character begins with a 1; this keeps the codes of the form 0abcdefg always available, since they are needed to represent control characters.
However, from the standpoint of truly unbiased internationalization, it would seem desirable to change the way in which shifted modes work. As shown here, it is easy enough to set up a mode in which a Chinese-language text interspersed with English-language portions is represented by two bytes for each Chinese character and one byte for each English letter. But it isn't possible to achieve equal efficiency if one is instead dealing with a Chinese-language text combined with Greek or Russian quotations.
Replacing 10 with 01, where the first byte already specified the length of the code, was used to indicate that the character also caused a shift to its own region of the available characters. Since 00 and 11 are also available, one can define two additional shift regimes, which, unlike the original one, do not transform the interpretation of characters as comprehensively.
With 00, the modes would be of this type:
110ABCDe 00fghijk - character ABCDefghijk - shift into mode where 0pqrstuv means character ABCDpqrstuv if p and q are not both zero, and 000000rstuv otherwise 1110ABCD 10Efghij 00klmnop - character ABCDEfghijklmnop - shift into mode where 0pqrstuv means character ABCDEfghipqrstuv if p and q are not both zero, and 00000000000rstuv otherwise
with 00 in the last position, and with 00 in the second-last position, we would have instead cases such as:
11110ABC 10DEfghi 00jklmno 10pqrstu - character ABCDEfghijklmnopqrstu - shift into mode where 110RSTUv 00wxyzab means character ABCDEfghijRSTUvwxyzab
and in this case, multiple modes of this form could be active at one time, so that one can specify that characters of the form 0PQrstuv belong to the Greek or Russian character set (while characters of the form 000rstuv remain control characters) and that characters of the form
110ABCDe 10fghijk
belong to the Chinese character set, or at least a chosen group of 2,048 contiguous characters from it.
Naturally, if 00 replaces 10 in the third-from last character, it is the interpretation of characters of the form
1110ABCD 10Efghij 10klmnop
that is modified, and so on.
Thus, so far, we have the situation where 01 replacing 10 sets up a shifted mode in which a byte beginning with 1 begins a fixed-length code representing a character in a selected portion of the code table, and 00 replacing 10 sets up a shifted mode in which the normal interpretation of the bits indicating the type of a code are retained, but standard UTF-8 character sequences of a specific chosen length are now shifted to refer to a different part of the code table.
The obvious thing to do next is to have 11 replacing 10 set up a shifted mode affecting the more efficient multibyte coding indicated by a combination whose first byte is of the form 10xxxxxx. Since this group of codes involves two-character combinations with 13 bits of information, three-character combinations with 20 bits of information, and so on, this would begin with having 11 replacing 10 in the second-last character:
11110ABC 10DEfghi 11jklmno 10pqrstu - character ABCDEfghijklmnopqrstu - shift into mode where 10vwxyza 0bcdeFGH means character ABCDEfghvwxyzabcdFGH (note that FGH are capitals in order to be distinct symbols, not to indicate they cannot all be zero, as of course they can)
As with the codes involving 00 replacing 10, these codes don't affect the parsing of character sequences, only the final meaning attached to a character, and thus multiple shift modes of the 11 type and multiple shift modes of the 00 type may all be simultaneously in effect. On the other hand, only one shift mode of the 01 type can be in effect at a given time, and when such a shift mode is in effect, no other shift modes can apply either.
With 11 in the second-last byte, we are creating a shifted expanse of 8,192 characters instead of 2,048 characters; thus, when combining Chinese with Greek or Russian, it would make sense to use a 00 shift mode for Greek or Russian and a 11 shift mode for Chinese.
However, there is one problem when 00 replaces 10 in the last byte of a multibyte character sequence. The fact that characters of the form 000xxxxx are not affected, while necessary to ensure the control characters always remain available, creates a conflict between the operation of these shift codes and the structure of the UNICODE code table, which, after the first 256 characters, does not treat the first 32 characters of each group of 128 characters in a special way.
The simple shift mode with 01 replacing 10 does not have this problem, although it has its own limitations.
Since 11, in the codes defined so far, can replace 10 in the second-last byte and in earlier ones, but not in the last byte, there is a remedy available:
110ABCDe 11fghijk - character ABCDefghijk - shift into mode where 00qrstuv means character 00000qrstuv, and character 01qrstuv means character ABCDeqrstuv.
This general type of coding allows any group of 64 characters defined by all but the last six bits to be made available in single-byte codes, while keeping not only the control characters, but the digits and common punctuation marks, always available.
It may well be more commonly used than the one with 00 replacing 10 in the last byte of a multibyte character code. But there may also be cases in which that one is more appropriate, since some languages use their own digits and punctuation marks, and require more than 64 character codes, but less than 96.