This section looks at cipher machines that worked with teletypewriters.
Just as today's computers represent printed characters as 8-bit bytes using the ASCII code, teletypewriters used a similar code for communications purposes. However, they used only five bits per character, which conserved bandwidth, although it meant that shifting between letters and other characters such as numbers and punctuation marks required sending characters that indicated a shift was taking place.
Thus, we have a family of cipher machines that, before the computer age, was already working in binary code.
Two early American attempts at a telecipher machine were not used in practice, since they were found to be insecure. One was designed by Gilbert S. Vernam for A. T. & T., the two-tape machine, where two punched tape loops of unequal size each provided a current character to be XORed with the plaintext character. The other was devised by Col. Parker Hitt, who was one of America's foremost cryptologists of the World War I era, for ITT, and involved ten cams with 96, 97, 98, 99, 100, 101, 102, 103, 104, and 105 positions, two of which supplied the bits to be XORed with one bit of the current plaintext character.
The XOR or exclusive-or logical operation is the simplest possible way to apply a key to a plaintext to conceal it. This operation is also modulo-2 addition, with the very small table:
| 0 1 ---+------- 0 | 0 1 1 | 1 0
If we view 0 as standing for "False", and 1 as standing for "True", then A exclusive-or B is true if either A is true exclusively (that is, A is true and B is false), or if B is true exclusively (B is true and A is false).
However, the machine devised by Vernam was modified to a form which was secure, and many countries have used similar devices. Instead of increasing the number of punched tape loops used to XOR with the plaintext, the number of key inputs was reduced from two to just one: and that one took a key tape consisting of completely random bits, used only once.
This, the one-time tape, is again the perfect case of polyalphabeticity, which was previously noted as the one-time pad under pencil-and-paper methods.
If anyone is unfamiliar with the alphabet used for 5-level teletypewriters, which is called the Baudot code (although, more accurately, it is in fact derived, with slight modifications, from the Murray code, a later 5-unit printing telegraph code, just as the code for transmitting chess moves by telegraph is called the Uedemann code, for the first person to invent such a code, even though the code actually used is a later one, properly known as Gringmuth notation; also, the International Morse Code, though it has several characters in common with the code of dots and dashes originally devised by Samuel Findley Breese Morse, is actually a revision of his code devised by one Frederick Gerke from Austria, as I have recently learned thanks to Terry Ritter) a table of it is given here.
(In the interests of making complete information handy, the table included is one with some additional information from one of my USENET posts.)
International Telegraph Alphabet No. 5 is the international version of ASCII;
International Telegraph Alphabet No. 1 was a version of Emile Baudot's original 5-unit code, the one that included a 'letters space' and a 'figures space'. (I've seen a web site that incorrectly claims that International Morse, formerly Continental Morse, was ITA 1.)
International Telegraph Alphabet No. 2 is what is most commonly called Baudot; it is the 5-level code derived from the Murray code.
ITA 3 and ITA 4 are obscure, but they are both derived from ITA 2, as are a couple of other codes.
The final code, ten bits long, is AUTOSPEC. All the codes, except for CCIR 476, are shown in order of transmission; CCIR 476 is shown the other way around, being assumed to be sent LSB first as is ASCII.
Characters ITA 2 ITA 4 ITA 3 CCIR 476 AUTOSPEC
(ITA 2 on left,
some national
ones follow)
Character 32 00000 100000 0000111 1101010 0000000000
Space 00100 000100 1101000 1011100 0010011011
Q 1 11101 011101 0001101 0101110 1110111101 Q 1 q !
W 2 11001 011001 0100101 0100111 1100100110 W 2 w
E 3 10000 010000 0111000 1010110 1000001111 E 3 e
R 4 01010 001010 1100100 1010101 0101001010 R 4 r $
T 5 00001 000001 1000101 1110100 0000111110 T 5 t
Y 6 10101 010101 0010101 0101011 1010101010 Y 6 y ^
U 7 11100 011100 0110010 1001110 1110000011 U 7 u &
I 8 01100 001100 1110000 1001101 0110001100 I 8 i
O 9 00011 000011 1000110 1110001 0001100011 O 9 o ~
P 0 01101 001101 1001010 0101101 0110110010 P 0 p
A - 11000 011000 0011010 1000111 1100011000 A - a _
S ' BEL 10100 010100 0101010 1001011 1010010100 S ' s "
D WRU $ 10010 010010 0011100 1010011 1001010010 D d
F % ! 10110 010110 0010011 0011011 1011001001 F % f `
G @ & 01011 001011 1100001 0110101 0101110100 G @ g }
H � # STOP 00101 000101 1010010 1101001 0010100101 H # h {
J BEL ' 11010 011010 0100011 0010111 1101000101 J * j
K ( 11110 011110 0001011 0011110 1111011110 K ( k [
L ) 01001 001001 1100010 1100101 0100101001 L ) l ]
Z + " 10001 010001 0110001 1100011 1000110001 Z + z
X / 10111 010111 0010110 0111010 1011110111 X / x \
C : 01110 001110 1001100 0011101 0111010001 C : c ;
V = ; 01111 001111 1001001 0111100 0111101111 V = v |
B ? 10011 010011 0011001 1110010 1001101100 B ? b
N , 00110 000110 1010100 1011001 0011000110 N , n <
M . 00111 000111 1010001 0111001 0011111000 M . m >
CR 00010 000010 1000011 1111000 0001011101
LF 01000 001000 1011000 1101100 0100010111
FIGS 11011 011011 0100110 0110110 1101111011
LTRS 11111 011111 0001110 1011010 1111100000
alpha (all 0) 000000 0101001 0001111
beta (all 1) 111111 0101100 0110011
SYNC 110011
repetition 0110100 1100110
Unlike ITA 3, CCIR 476 has a pattern that relates it to ITA 2: except for the letters B and U, whose natural codes are used for alpha and beta, those ITA 2 characters which have 4, 3, or 2 one bits set are represented by 0x0, 0x1, and 1x1 respectively, where x is the five bits of the ITA 2 character; and 1nnnnn0 represents the characters that don't fit into this range, with again exactly 3 of the n bits set. Note that ITA 3 is a 3 of 7 code, while CCIR 476 is a 4 of 7 code.
Perhaps this is why the newer CCIR 476 is the one US radio amateurs are permitted to use, and do use for AMTOR, while the older ITA 3 was used for ARQ purposes originally. But it's odd to see a new code developed to fill exactly the same purpose as an older code already accepted as an international standard.
ITA 3 was known as, or derived from, the Moore ARQ code, also known as the RCA code. It appears to have been the first code used for ARQ (automatic repeat request) purposes, and to have been invented in or prior to 1946 by H. C. A. van Duuren. ITA 3 was adopted as an international standard in 1956, according to the source which first brought him to my attention.
AUTOSPEC repeats the five-bit character twice, but if the character is one with odd parity, the repetition is inverted. Thus, the parity bit is transmitted with high reliability, and every other bit of the character is effectively repeated twice. It can be thought of the result of applying an error-correcting code with the matrix:
1 0 0 0 0 0 1 1 1 1 0 1 0 0 0 1 0 1 1 1 0 0 1 0 0 1 1 0 1 1 0 0 0 1 0 1 1 1 0 1 0 0 0 0 1 1 1 1 1 0
to 5-level characters.
The entries
F % ! and V = ;
mean that, for F, no figures shift character is defined by ITA 2; however, the % sign is uses as a national-use figures shift character for Britain. The U.S. figures shift character is !. For V, however, the = sign is defined as the official figures shift character. The U.S. 5-unit teletypewriter code, which is nonconformant to ITA 2, defines ; as the figures shift character for V instead.
After the code bits, there are four more columns of characters, giving the characters used by ASCII over AMTOR. The all-zeroes character is used to toggle between the ordinary character set in the first two columns, and the auxilliary one in the second two. The ordinary character set is that of the international version of the 5-level code, rather than the U.S. version, but the figures shift of J, instead of being the bell, is the asterisk.
Note that there is also an official standard of very recent vintage for using lowercase with 5-level code, which works on a different principle: a LTRS code while already in letters case is used to toggle between upper and lower case.
This standard does not include ASCII graphics characters, but it was designed to be compatible with the use of the all-zeroes code for supplementary alphabetic characters; these characters could have their lower case available using their shift character in the same fashion as LTRS is used.
This new standard works as follows: FIGS LTRS operates as a reset into upper-case mode. In normal upper-case mode, when returning to letters case from figures case, one is returning to upper-case letters.
When in letters case, a superfluous LTRS code switches into lower-case. This is true even when reset into upper-case mode; but then it also clears lower-case mode, so that, whether one is printing upper-case or lower-case, when one returns from printing figures characters to print letters, one begins with lower-case letters.
This is a bit confusing, so I will illustrate it:
ABC [FIGS] 1234 [LTRS] DEF [LTRS] ghi [FIGS] 1234 [LTRS] jkl [LTRS] MNOPQ [FIGS] 1234 [LTRS] rst [FIGS][LTRS] UVW [FIGS] 1234 [LTRS] XYZ
Essentially, toggling between upper and lower case with a superfluous LTRS is always on. FIGS LTRS resets (to upper-case, or capitals) only the default letters case that a normal LTRS, used for exiting figures printing, returns to. And that default flips back to lower case the first time lower case is accessed with an (otherwise) superflous LTRS.
Thus, this example proceeds as follows:
ABC [FIGS] 1234 [LTRS] DEF
One begins by having only figures and upper-case letters available.
[LTRS] ghi [FIGS] 1234 [LTRS] jkl
The superfluous LTRS now switches one into lower-case mode, as well as immediately switching to printing lower-case letters. The FIGS shift still takes you to normal figures case, and a LTRS shift returns you to lower-case letters.
[LTRS] MNOPQ [FIGS] 1234 [LTRS] rst
A superfluous LTRS shift changes you to printing upper-case characters, but the mode remains lower-case mode. Thus, FIGS takes you to printing digits, and LTRS takes you to printing in the default case for the current mode, which is lower case.
[FIGS][LTRS] UVW [FIGS] 1234 [LTRS] XYZ
A superfluous LTRS toggles between printing upper-case and lower-case, but only moves you from upper-case mode to lower-case mode. To change mode in the reverse direction, the combination FIGS LTRS is required. Once that combination is used, not only do you print in upper-case, but a LTRS shift used after printing figures will return you to the new default case, which is again upper case.
The bits are numbered from 1 to 5, in the order in which they are transmitted. They are normally preceded by one start bit (0) and followed by one and a half stop bits - that is, a 1 level on the wire for one and a half times the time used for transmitting a data bit. In ASCII, the bits of a character are transmitted least significant bit first; since the 5-level code bits don't represent codes in any kind of numerical order, sometimes bit 5 and sometimes bit 1 is taken as the most significant bit, although the tendency has been to treat bit 5 as the MSB because of the use of the same UART chips for ASCII and 5-level code.
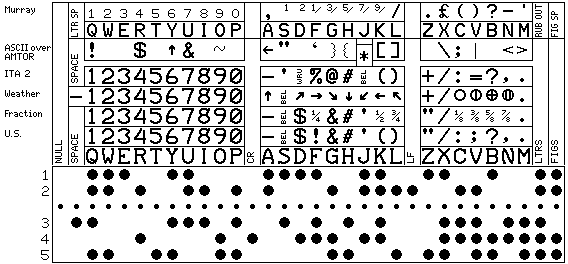
And here is a graphical version, showing the standard, U.S., financial, and weather character sets:
The top two lines show the original Murray code, from which the modern 5-level code is derived. (The original Baudot code was completely different.) It too, like the original Baudot, used a letters space and a figures space. I'm not sure about the functions of the line feed and carriage return characters: one of them could be a newline, and the other might have had a different control function. Also, in my reference, the space for the figures shift of A was left blank. My guess is that that should have been a comma.
Incidentally, the reason that this code is not so organized that when the letters are in alphabetical order, their codes are in binary numerical order, as is the case for ASCII, is because the codes were chosen so that the most common letters would have codes that would cause less wear and tear on the moving parts of teleprinters. The following chart shows the scheme by which the codes were assigned:
lsc lf EfprT AINO UCM KV SRH DL FG TP BW QX tiYZ 1 * * * * * * * * ** ** **** 2 * ** ** ** * * * ** * * ** ......................................... 3 * ** *** ** * * * * ** * * 4 * ** ** ** * * ** * * * ** 5 * * * * * * * * ** ** ****